 万万没想到
万万没想到
XDM免费开源的全能下载工具-让你的下载快人十步-榨干你的带宽
你们平时会不会遇到一些网站下载限速的问题呢?或者是总感觉自己的浏览器下载总是跑不满我们的带宽,而且我们有时需要下载一些视频网站的视频或者歌曲,但是官方并不给你开启下载权限,那么好,今天的这款软件统统帮你解决,来让这款软件帮助你跑爆你的带宽吧...
你们平时会不会遇到一些网站下载限速的问题呢?或者是总感觉自己的浏览器下载总是跑不满我们的带宽,而且我们有时需要下载一些视频网站的视频或者歌曲,但是官方并不给你开启下载权限,那么好,今天的这款软件统统帮你解决,来让这款软件帮助你跑爆你的带宽吧...

大家有没有发现,我们的电脑随着我们使用的时间的增长,里面的文件越来越多,我们的桌面也越来越满,时不时得清理了,一些文件也被我们移入了磁盘文件夹中;这样我们有的时候找文件就会越来越费力,一眼望去,一排排的文件真是搞得我们头昏眼花。

centos7 密码忘了怎么办?教你进入紧急模式,恢复找回密码。
屏幕录制软件是我们生活中某些人群会经常用的软件,但是现在市面上的录屏软件良莠不齐,大部分使用难度大,功能不全,好用 的录屏软件大多付费,让人苦不堪言。 今天就为大家介绍一款,简单实用,功能强大,免费开源的录屏软件,在GitHub上是可以找到...

我的第一篇博客!真的是好难啊 这个东西 杂七杂八的 搞了半天才搞出个雏形。 第一篇博客,该写些什么呢?现在我也没有什么好的主题,那就跟大家分享一下我这次的搭建过程吧。 一.搭建前的准备 1.一台服务器(国内的需要备案才能正常建站,国外的没有...


简单理解为从其他模型如Qwen 7B中提取知识来训练自己,旨在减小模型大小,提供更高效的推理能力。
LLM(Large Language Model )大语言模型
在深度学习中,模型的权重和激活值通常使用高精度的浮点数表示,如 32 位浮点数(FP32)。量化技术将这些高精度的浮点数转换为低精度的定点数或整数表示,如 8 位整数(INT8)。这么做的作用就是减少存储空间的占用、加速推理速度、减少GPU资源的占用,但是会损失一定的模型精度。
DeepSeeK Github:“Since FP8 training is natively adopted in our framework, we only provide FP8 weights. If you require BF16 weights for experimentation, you can use the provided conversion script to perform the transformation.”
DeepSeek官方提供的满血版模型为FP8量化,官方提供的其余蒸馏版本为BF16量化。
Ollama提供的模型均为INT4量化。
BF16(bfloat16,Brain Floating Point 16) 格式的结构与标准的 FP32(32 位浮点数)相似,包含 1 位符号位、8 位指数位和 7 位尾数位。与传统的 FP16 格式不同,FP16 的尾数部分有 10 位,而 BF16 则减少到了 7 位,牺牲了一些精度,但保留了更大的指数范围,使其在处理大范围的数值时更加稳定。
BF16 格式的一个重要特点是,它在计算过程中能够与 FP32 格式兼容,因此它在处理深度学习模型时,不需要大幅度改变原有的计算流程,从而提供了很好的计算效率。
b(billion),表示模型的参数数目为 x 十亿个,7b = 70亿, 32b = 320亿
VRAM (Video Random-Access Memory):
VRAM 是一种专门用于图形卡的内存类型,设计上主要用于存储图像和视频数据。它是 DRAM 的一种变体,专门用于加速图形处理和提高图形性能。与 DRAM 不同,VRAM 具有双端口设计,即可以同时进行读取和写入操作,这对图形处理非常重要,能够大幅提升显示设备的性能。在图形渲染过程中,VRAM 存储的内容包括纹理、图像数据和视频缓冲区等,保证图形的流畅输出。
总结:VRAM:显卡内存,专门用于图形处理和视频显示,提升图形性能。
DRAM (Dynamic Random-Access Memory):
DRAM 是一种常见的内存类型,用于计算机的主内存。它以“动态”方式存储数据,即需要定期刷新电容来保持数据的完整性。DRAM 相较于其他类型的内存(比如 SRAM)成本较低,但速度较慢,因此通常作为系统的主内存使用。每个内存单元由一个电容和一个晶体管组成,电容会随着时间消耗电荷,因此需要不断刷新来保持数据。
总结:DRAM:系统内存,负责存储计算机当前运行的程序和数据。
RAG “Retrieval-Augmented Generation” 检索增强生成
大模型的数据一般是静态的,无法覆盖最新或特定领域知识,RAG技术就允许动态引入外部知识库(如内部文档、新闻等),引用知识库中的内容来总结回答,减少幻觉,可大大提升LLM的时效性和专业性。
MCP 全称 Model Context Protocol,模型上下文协议,是 Anturopic 公司在2024年11月推出的一种开放协议,旨在统一规范大语言模型与外部数据源和工具之间的通信。
话不多说,先上一张图,我想大家已经懂了,谁现在工作中没经历过这样的痛苦呢?一个产品文档几百上千页,找些想要的信息可谓大海捞针,关键字匹配一下匹配到65535个结果......(wdnmd)
RAG(Retrieval-Augmented Generation,检索增强生成)
大模型的数据一般是静态的,无法覆盖最新或特定领域知识,RAG技术就允许动态引入外部知识库(如内部文档、新闻等),引用知识库中的内容来总结回答,减少幻觉,可大大提升LLM的时效性和专业性。
现在,利用RAG技术,我们每个人都可以拥有一个私人全能专家顾问,有什么问题,说人话就可以得到想要的答案!
外面找家人力公司,让其提供人员
优点:省心、快速、立即上岗
缺点:可能 我说可能人品不行,偷东西,有跑路风险,干的越多要的越多,钱从你钱包一张张抽出,容易焦虑(tokens)
人力公司推荐:硅基流动【链接直达】
家里花钱培养一个,让其为我们服务
优点:诚实、可靠、听话、可调教
缺点:培养成本高、培养难度大
如何培养?看看我的经验:
【2025最新】Linux服务器部署DeepSeek-R1操作实践 | 企业级AI框架完整方案(Ollama)
【手把手教学】Windows系统部署DeepSeek-R1全攻略 | 本地部署实践指南(Ollama)
好,那现在我默认大家都已经找到自己的专家了。
首先要有一个工具来展示和记录我们提出的问题和专家给出的答案。
Cherry Studio(开源)【下载地址】下载并完成安装。
来到官网,如果没有账号先注册一个账号,通过我的邀请链接,我们各能获取到2000万Tokens。
[突然正经] 登录成功之后会跳转到模型广场,这里有各种各样我们可以调用的模型,我们来生成API秘钥来对接到刚才下载的Cherry Studio上。
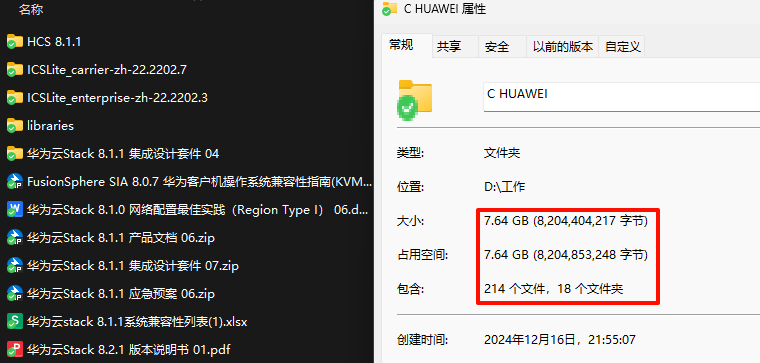
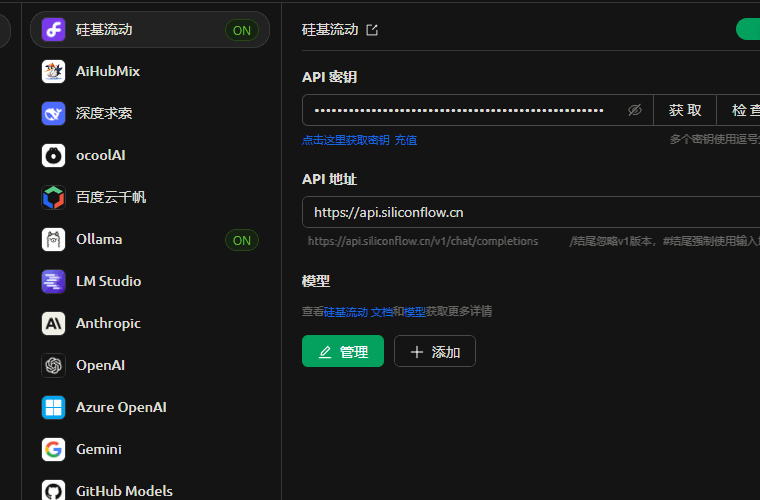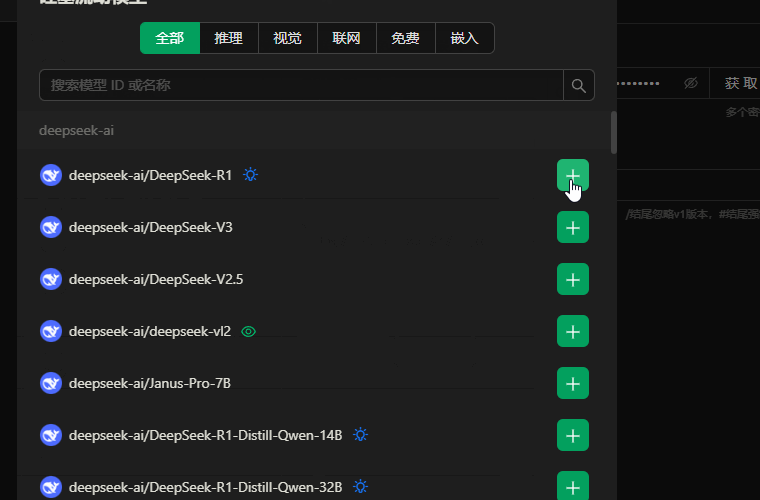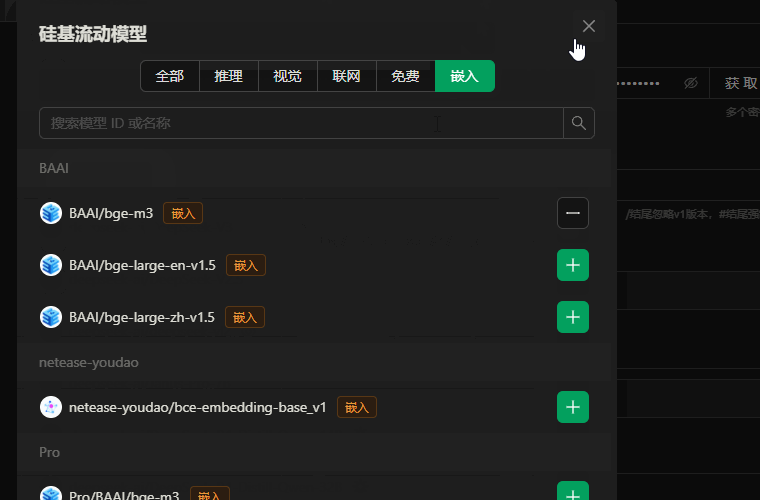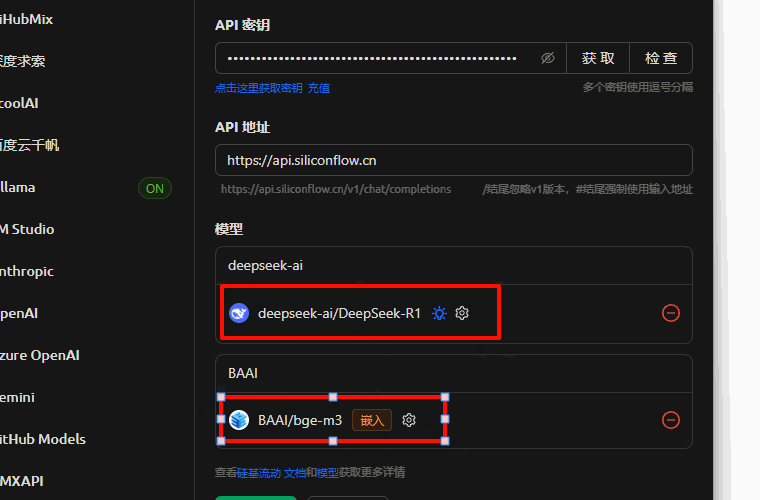
左侧导航栏选择 “API 秘钥” ->"新建API密钥" -> 描述"Cherry Studio" -> "新建密钥" 单击进行复制

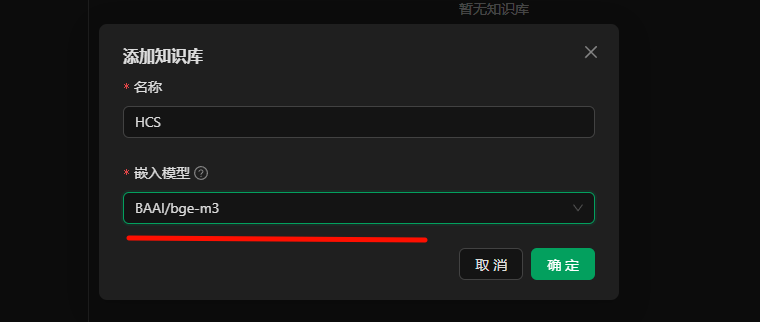
来到Cherry Studio,左侧导航栏最下方 "设置" 按钮 -> "模型服务" -> "硅基流动" -> "API秘钥" 处粘贴刚复制的秘钥 -> "管理" -> 添加 "deepseek-ai/DeepSeek-R1" -> "嵌入" 添加"BAAI/bge-m3"
主要添加两个模型:“deepseek-ai/DeepSeek-R1”,“BAAI/bge-m3”
BAAI/bge-m3模型:BGE-M3 是一个多功能、多语言、多粒度的文本嵌入模型。它支持三种常见的检索功能:密集检索、多向量检索和稀疏检索。该模型可以处理超过100种语言,并且能够处理从短句到长达8192个词元的长文档等不同粒度的输入。这里我们主要作为语义向量模型使用,用于解析我们上传的知识库,将文本转化为向量。
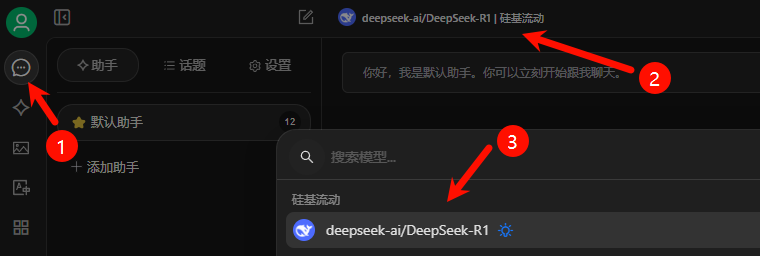
回到助手功能区,按下图顺序选择刚才添加的R1模型,随机发送内容测试是否可用。
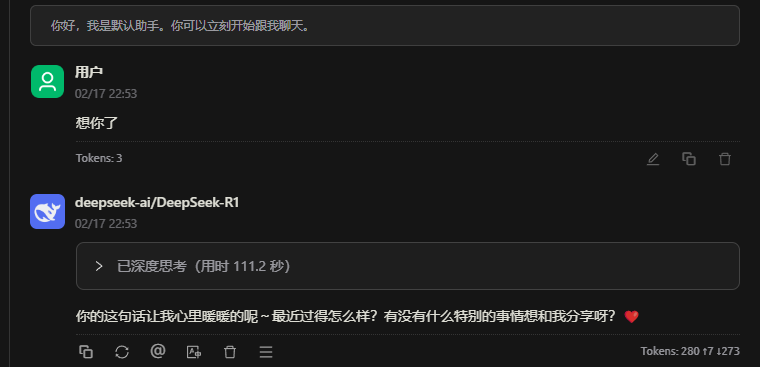
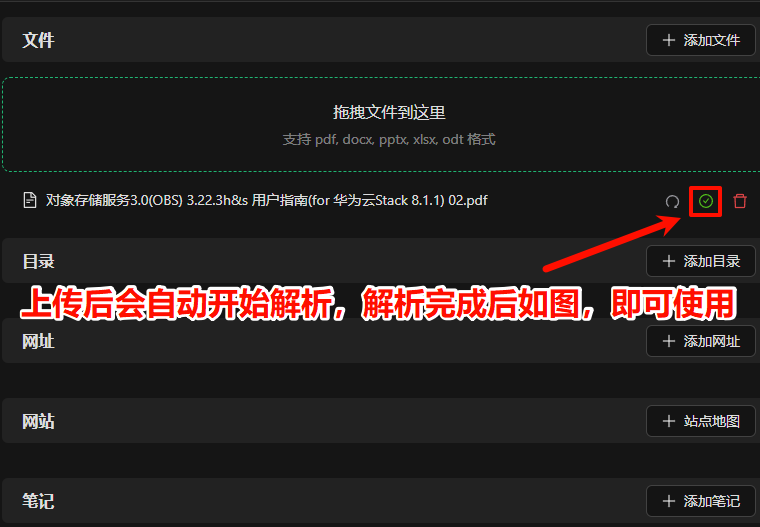
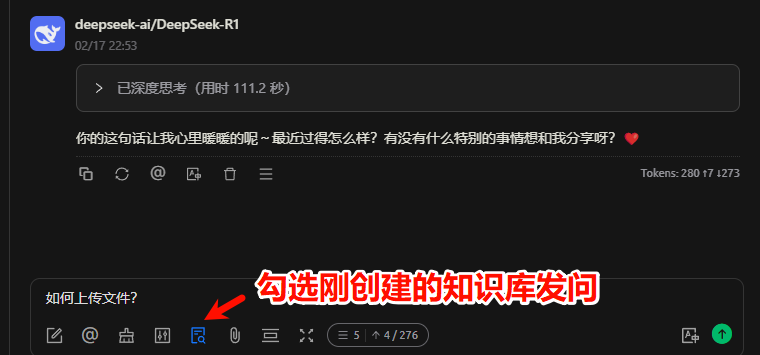
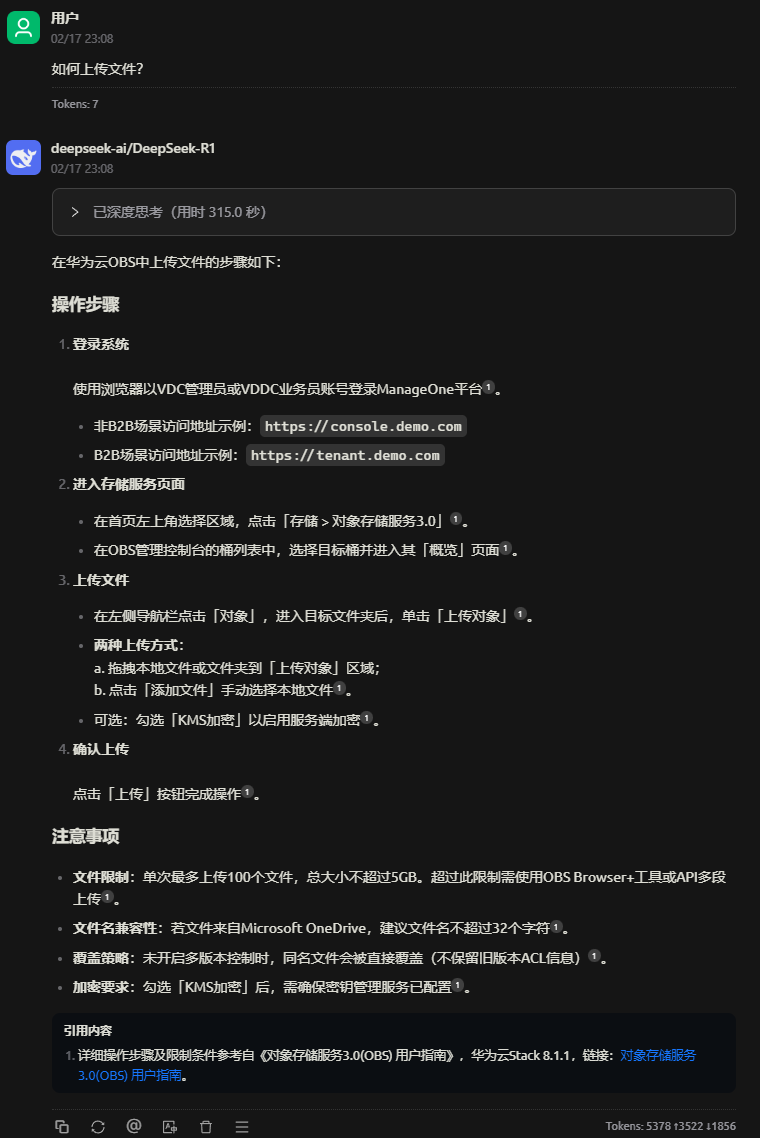
回复无误,可见引用的具体知识库中文档。
Ollama部署主机上执行:
ollama pull bge-m3拉取成功即可,即可在后面步骤选中。
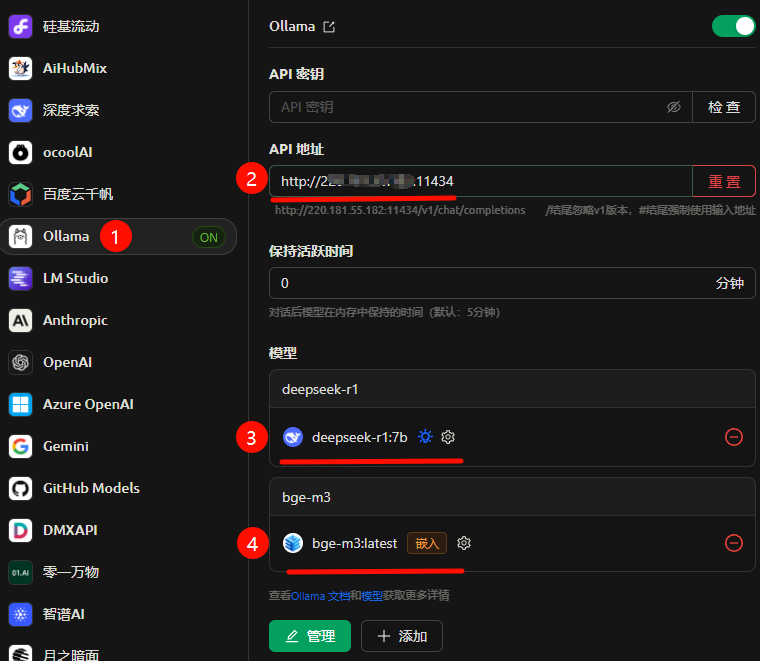
与上面对接硅基流动基本无差别,只需要修改API地址为我们部署的主机地址及端口即可。
略
略
略
步骤 3 4 5 内容重复无区别,可参考“外面找的硅基流动”章节进行配置。
问题就是标题所说的只能个人使用,为什么?因为使用 Cherry Studio 创建的知识库和向量数据库都是存在本地电脑的,数据不能共享,所以无法团队使用。那么如何部署一个团队可用的知识库智能体呢?
且听下回分解(码字中)......
DeepSeek是一家大模型初创公司,全称“杭州深度求索人工智能基础技术研究有限公司”,因2025年1月份发布并直接开源的DeepSeek-R1及V3模型被大众所熟知,此模型由中国团队自主研发,参数高达670亿,性能对标 OpenAI o1 正式版,一经发布是吓得OpenAI紧急发布尚不完善的o3模型,命名为o3-mini,这意味着中国在 AI 领域的技术实力大幅度增强,不仅提升了国内科技产业的竞争力,还推动了全球科技格局的变化。
操作系统:Linux
硬件准备:没啥要求,现在市面的设备基本都可以跑,满血版跑不起来,咱1.5b的蒸馏版还跑不起来?
对于DeepSeek官方开源的版本,也就是我们常说的671b满血版本,本地PC部署基本是不可能的,因其模型大小约为404GB,在模型启动运行时,需要将所有数据全部加载至内存中,且根据量化值的大小占用有所不同,如8bit量化则内存占用较4bit将近乎翻倍,所以本地PC部署此版本几乎不太可能。
本地体验建议使用蒸馏版本模型,相对较小,且不必依赖强大的数据中心级GPU,如不在乎生成速度,CPU也能跑,常见有以下几个版本:
| 模型名称 | 模型大小 | 备注 |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.1GB | 基于qwen蒸馏 |
| DeepSeek-R1-Distill-Qwen-7B | 4.7GB | 基于qwen蒸馏 |
| DeepSeek-R1-Distill-Llama-8B | 4.9GB | 基于llama蒸馏 |
| DeepSeek-R1-Distill-Qwen-14B | 9.0GB | 基于qwen蒸馏 |
| DeepSeek-R1-Distill-Qwen-32B | 20GB | 基于qwen蒸馏 |
| DeepSeek-R1-Distill-Llama-70B | 43GB | 基于llama蒸馏 |
| DeepSeek-R1 671B | 404GB | 未蒸馏 |
云主机1台,3块英伟达T4显卡 (16GB VRAM)直通。
| 云主机 *1 | 系统 | Ubuntu22.04LTS |
| CPU | 32核 | |
| 内存 | 128 GB | |
| 硬盘 | 1TB SSD | |
| GPU | 3 * NVIDIA T4 (16GB) |
Ollama官网:Ollama
curl -fsSL https://ollama.com/install.sh | shLinux终端执行此脚本即可自动安装Ollama和对应显卡驱动(通过脚本查询GPU品牌自动下载安装驱动)
安装完成后测试安装是否正常:
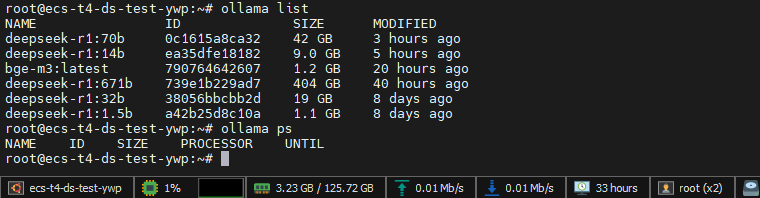
ollama list 执行不报错,输出为空代表安装正常。
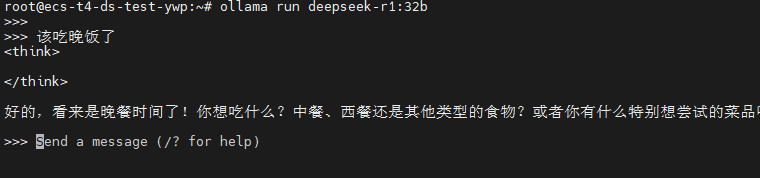
执行以下命令拉取32b参数模型:
ollama run deepseek-r1:32b拉取完成后即可进入对话界面,至此已可以本机对接使用。
但!
我们都服务器部署了,是不是得映射到互联网或发布到局域网来团队使用呢?
现在的状态是不可以被互联网和局域网访问的,因为Ollama默认启动的监听是在本地环回地址的:

我们需要稍微修改一下配置。
我们要通过修改环境变量来修改监听接口信息,使用官方脚本进行拉取的Ollama是通过Systemd来管理的,所以修改环境变量要修改 /etc/systemd/system/ollama.service 增加如下配置:
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"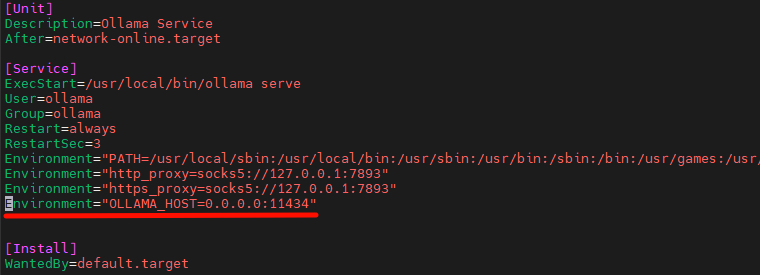
添加完成后保存退出:
systemctl daemon-reload
systemctl restart ollama.service
已经启用全部接口监听。现在可以通过局域网访问Ollama API接口,默认端口11434,可进行客户端的对接,如设备具有公网IP,则在无防火墙安全组等策略限制的情况下,已可以通过公网IP进行Ollama API调用。
客户端选择较为多样,Web客户端可选:WebUI、LobeChat,桌面客户端可选:WebUI、LobeChat等。
本次选用 AnythingLLM 作为演示,其他使用起来区别也不大,都是集成各模型服务厂商接口,如OpenAI、硅基流动、深度求索、月之暗面....... 到个平台申请API秘钥后即可直接调用。
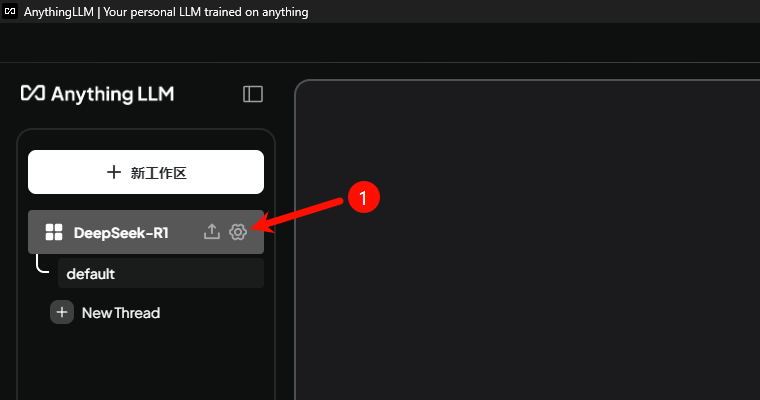
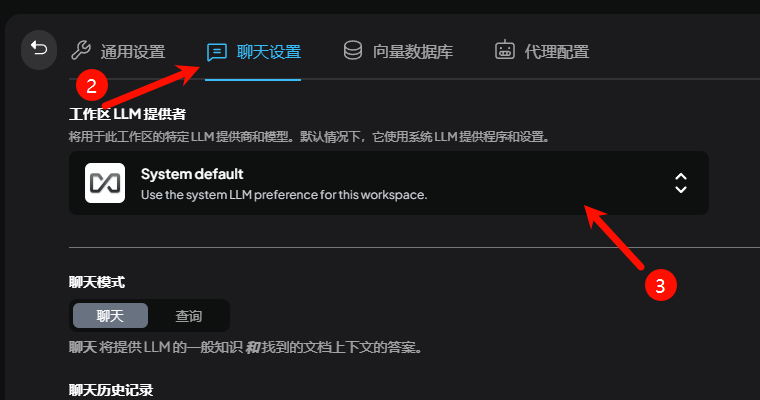

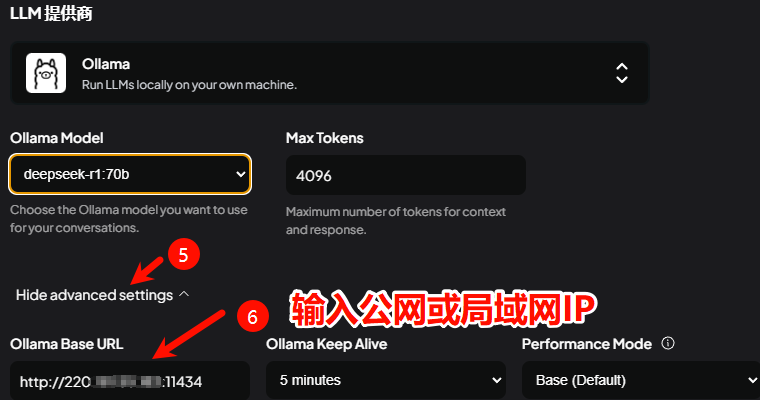
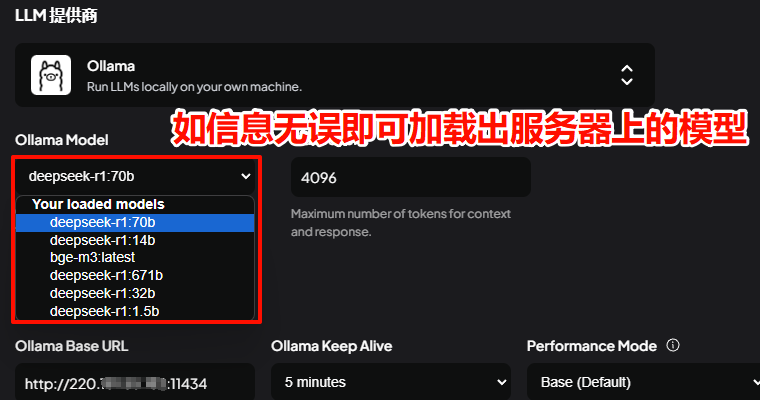

代理!开代理,代理搭建方法就不分享了,得自己想办法哈~
如何配置代理?
还是修改systemd Ollama配置文件,替换为自己的代理地址,/etc/systemd/system/ollama.service
[Service]
Environment="http_proxy=socks5://127.0.0.1:7893"
Environment="https_proxy=socks5://127.0.0.1:7893"systemctl daemon-reload
systemctl restart ollama.service配置完成后重新拉取即可。
详细报错:
Error: llama runner process has terminated: cudaMalloc failed: out of memory
ggml_gallocr_reserve_n: failed to allocate CUDA0 buffer of size 8822759424
llama_new_context_with_model: failed to allocate compute buffersVRAM不足,如无法增加显卡或配置,可考虑启动统一内存,以允许 GPU 在内存不足时使用 CPU 内存 。
启动统一内存方法(systemd 管理):
[Service]
Environment=GGML_CUDA_ENABLE_UNIFIED_MEMORY=1 #启动统一内存systemctl daemon-reload
systemctl restart ollama.service可能会发现模型可以跑了,但性能极低。
相关推荐:
DeepSeek是一家大模型初创公司,全称“杭州深度求索人工智能基础技术研究有限公司”,因2025年1月份发布并直接开源的DeepSeek-R1及V3模型被大众所熟知,此模型由中国团队自主研发,参数高达670亿,性能对标 OpenAI o1 正式版,一经发布是吓得OpenAI紧急发布尚不完善的o3模型,命名为o3-mini,这意味着中国在 AI 领域的技术实力大幅度增强,不仅提升了国内科技产业的竞争力,还推动了全球科技格局的变化。
操作系统:Windows
硬件准备:没啥要求,现在市面的设备基本都可以跑,满血版跑不起来,咱1.5b的蒸馏版还跑不起来?
对于DeepSeek官方开源的版本,也就是我们常说的671b满血版本,本地PC部署基本是不可能的,因其模型4bit量化后大小还在400GB以上,在模型启动运行时,需要将所有数据全部加载至内存中,且根据量化值的大小占用有所不同,如8bit量化则内存占用较4bit将近乎翻倍,所以本地PC部署此版本几乎不太可能。
本地体验建议使用蒸馏版本模型,相对较小,且不必依赖强大的数据中心级GPU,如不在乎生成速度,CPU也能跑,常见有以下几个版本:
| 模型名称 | 模型大小 | 备注 |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.1GB | 基于qwen蒸馏 |
| DeepSeek-R1-Distill-Qwen-7B | 4.7GB | 基于qwen蒸馏 |
| DeepSeek-R1-Distill-Llama-8B | 4.9GB | 基于llama蒸馏 |
| DeepSeek-R1-Distill-Qwen-14B | 9.0GB | 基于qwen蒸馏 |
| DeepSeek-R1-Distill-Qwen-32B | 20GB | 基于qwen蒸馏 |
| DeepSeek-R1-Distill-Llama-70B | 43GB | 基于llama蒸馏 |
| DeepSeek-R1 671B | 404GB | 未蒸馏,4bit量化 |
我电脑的配置为:Intel i7-12700K,32GB内存,1TB SSD,NVIDIA GeForce RTX 3070 8G显存。
这里使用DeepSeek-R1-Distill-Qwen-7B进行演示,各位可根据自己设备的配置进行模型选择
| PC *1 | 系统 | Win 11 24H2 |
| CPU | 20核 | |
| 内存 | 32 GB | |
| 硬盘 | 1TB SSD | |
| GPU | NVIDIA RTX 3070 8G |
为简化安装流程和降低使用门槛,尝鲜建议可使用Ollama进行部署,大部分开源客户端软件如Open WebUI、LobeChat、AnythingLLM、Cherry Studio等均支持Ollama API,可对接Ollama API后进行WEB或桌面端的使用。
Ollama官网:Ollama
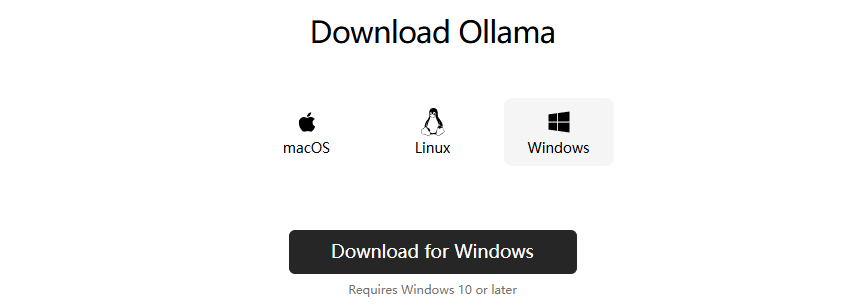
点击首页Download,根据系统进行选择,这里选择 Download for Windows
双击下载好的exe文件 install即可。
安装完成后会自动运行Ollama,打开PowerShell,输入Ollama回车,正常输出帮助信息代表安装成功。
Ollama支持模型清单:Ollama Model Search

ollama run deepseek-r1:7b
单击deepseek-r1,即可选择不同参数模型,这里选择7b,复制启动命令至PowerShell即可拉取并运行。
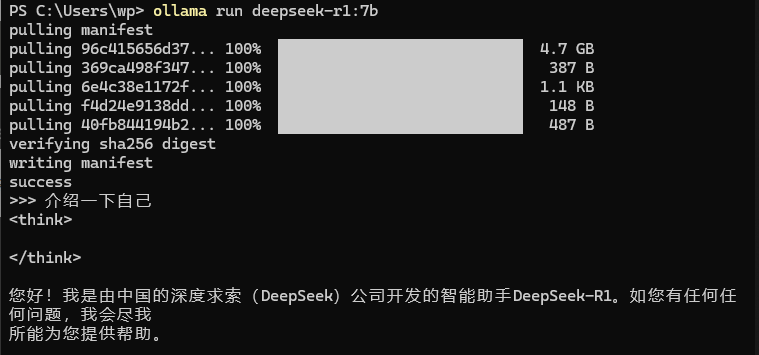
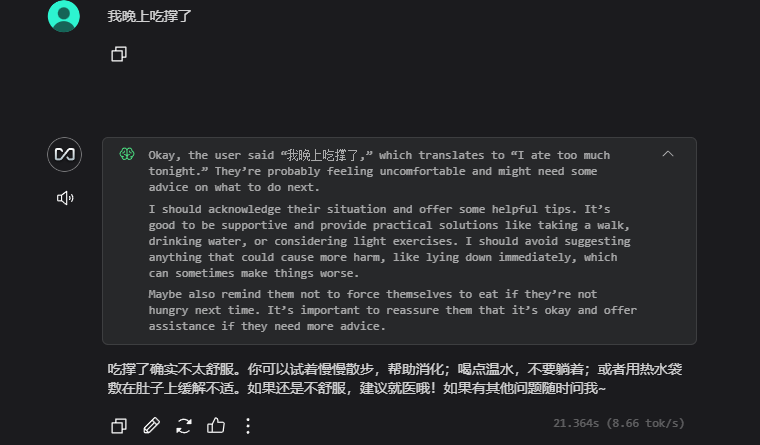
无报错,进入 >>> 对话模式与其对话,回答正常,安装部署成功。
客户端选择较为多样,Web客户端可选:WebUI、LobeChat,桌面客户端可选:WebUI、LobeChat等。

本次选用 Cherry Studio 作为演示,其他使用起来区别也不大,都是集成各模型服务厂商接口,如OpenAI、硅基流动、深度求索、月之暗面....... 到个平台申请API秘钥后即可直接调用。
Cherry Studio安装过程不再赘述,选择好安装位置,一路下一步即可。
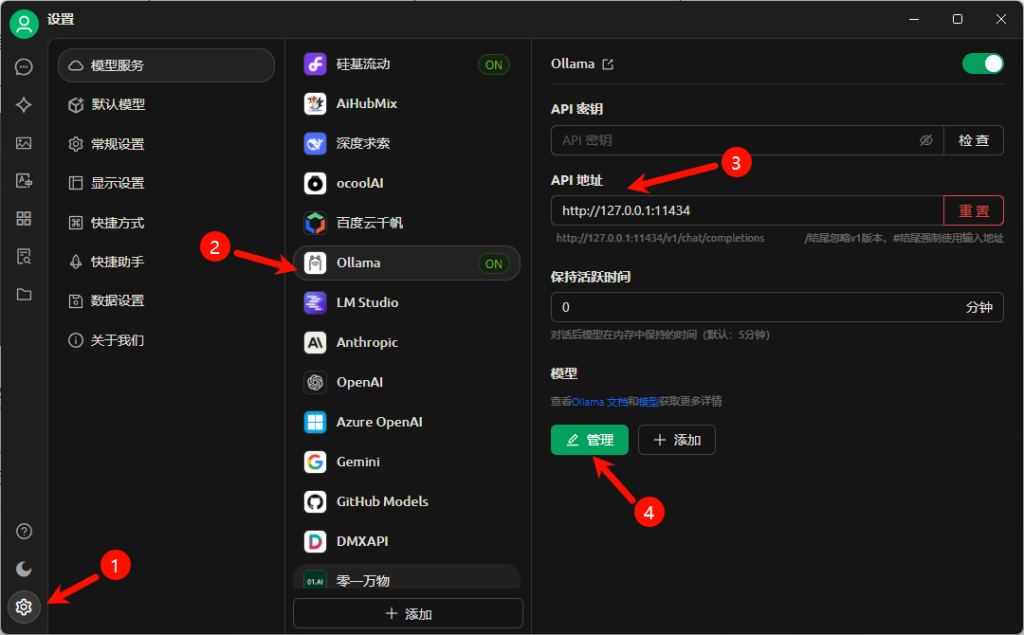
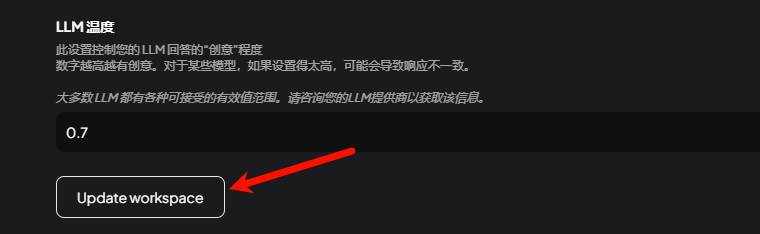
API地址:Ollama默认会启动 http://127.0.0.1:11434 端口的监听,输入到此处后点击管理,如成功连接至API,则会如下图列出已加载的模型列表,点击"+"添加。
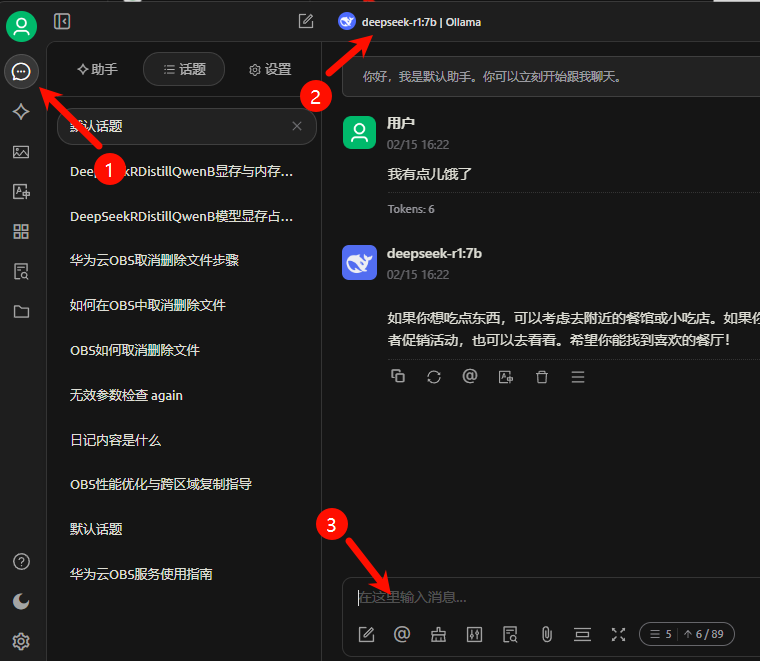
回到会话界面,选择本地部署的“deepseek-r1:7b | Ollama”模型即可开始对话。

推理过程中GPU及VRAM利用率如图。
相关推荐:
很奇怪,今天突然发现WordPress Redis Object Cache缓存插件报错无法连接到Redis了。
具体报错如下图:
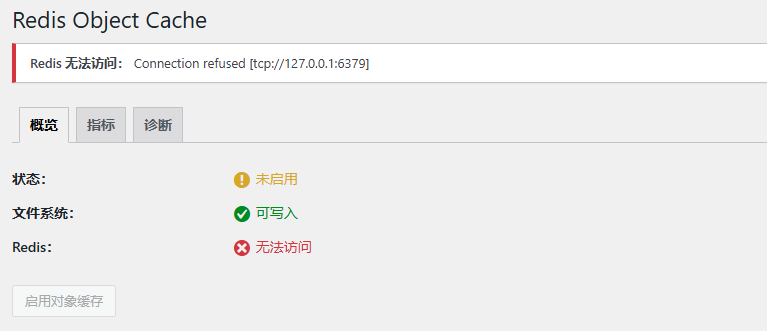
以为是 Redis 容器挂了,到主机上 tcping 了下 127.0.0.1 的 6379 端口,发现是通着的,顿时陷入了沉思······
来吧,老样子,介绍下环境:
查了半天,PHP Redis插件、redis容器运行状态及日志、php日志、OpenResty日志,都没发现问题······
最终排查出可能是因为插件自动升级的原因,导致原来插件的配置文件被覆盖成默认了,默认Redis服务地址为:127.0.0.1,传统环境下是没问题的,但是我们的 PHP 是 docker 容器化部署的,这就有问题了,如果填写 127.0.0.1 的话,去尝试连接的则是 PHP 容器内的127地址,所以肯定无法连接,那么我们把此地址改为容器名即可正常与Redis容器内应用通信,详细操作方法如下:
位置在网站根目录下的:/wp-content/plugins/redis-cache/includes/object-cache.php
默认为:
protected function build_parameters() {
$parameters = [
'scheme' => 'tcp',
'host' => '127.0.0.1',
'port' => 6379,
'database' => 0,
'timeout' => 1,
'read_timeout' => 1,
'retry_interval' => null,
'persistent' => false,
];修改为:
protected function build_parameters() {
$parameters = [
'scheme' => 'tcp',
'host' => '1Panel-redis-kKCk',
'port' => 6379,
'database' => 0,
'password' => 'password',
'timeout' => 1,
'read_timeout' => 1,
'retry_interval' => null,
'persistent' => false,
];修改涉及两处:
位置在网站根目录下:/wp-config.php
在最下方添加如下代码:
/** Redis Object Cache */
define( 'WP_REDIS_HOST', '1Panel-redis-kKCk' );
define( 'WP_REDIS_PORT', 6379 );
define( 'WP_REDIS_PASSWORD', 'password' );/** Redis设置了密码时填写 */保存。
之后回到 WordPress 控制台插件处刷新界面,开启即可。
![Redis Object Cache“Redis 无法访问: Connection refused [tcp://127.0.0.1:6379]”故障处理方法](https://oss.wanpeng.life/wp-content/uploads/2024/07/aaf5872f612cbb4.png)
因为可以理解为Docker默认内置了一个小型DNS服务器,记录了容器名和容器IP地址的对应的对应关系,所以可以直接通过主机名进行通信。
想看看?这样:
列出我们docker的网卡,找出容器在使用的,记录下来,比如:1panel-network
docker network ls
docker network inspect 1panel-network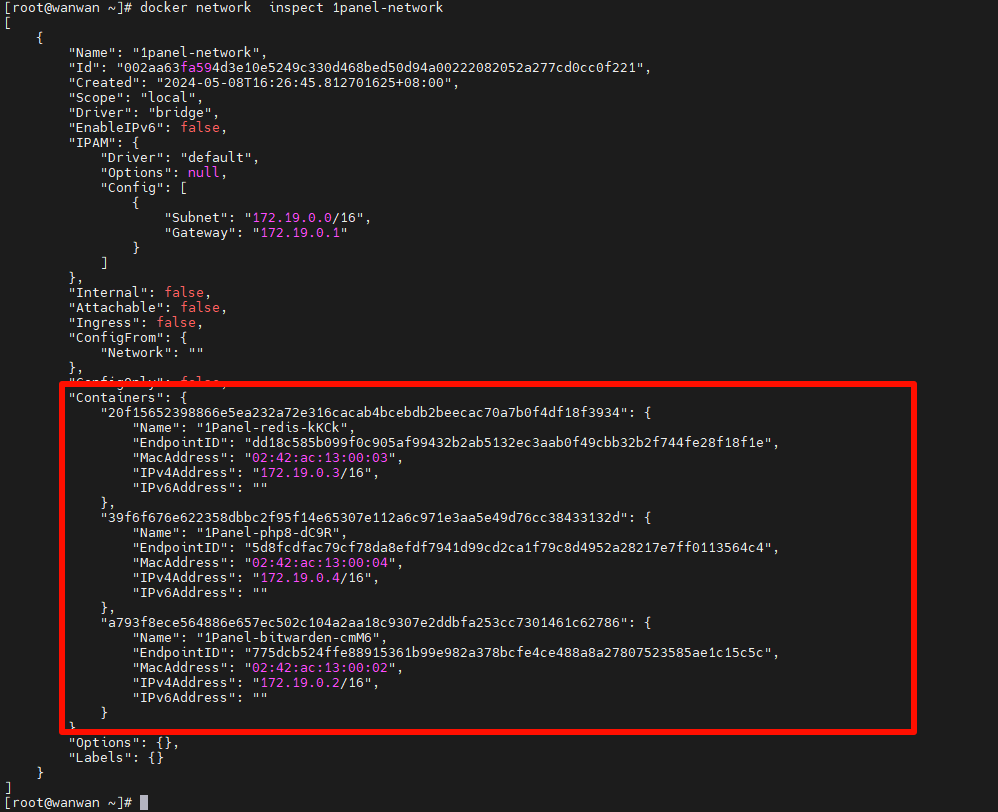
可以看到,这里就记录着我们Docker容器名和容器IP的对应关系。
由于腾讯文档是在线应用,腾讯可能随时对应用进行更新,有的时候发现用着用着突然就变样子了,常用的功能突然找不到了,不知道被挪到哪里去了······
最新的位置在:插入-->行列-->行高列宽-->自动调整行高列宽

这么常用的功能不知为何被藏得这么深~