 万万没想到
万万没想到一、DS 介绍
DeepSeek是一家大模型初创公司,全称“杭州深度求索人工智能基础技术研究有限公司”,因2025年1月份发布并直接开源的DeepSeek-R1及V3模型被大众所熟知,此模型由中国团队自主研发,参数高达670亿,性能对标 OpenAI o1 正式版,一经发布是吓得OpenAI紧急发布尚不完善的o3模型,命名为o3-mini,这意味着中国在 AI 领域的技术实力大幅度增强,不仅提升了国内科技产业的竞争力,还推动了全球科技格局的变化。
二、准备工作
操作系统:Linux
硬件准备:没啥要求,现在市面的设备基本都可以跑,满血版跑不起来,咱1.5b的蒸馏版还跑不起来?
对于DeepSeek官方开源的版本,也就是我们常说的671b满血版本,本地PC部署基本是不可能的,因其模型大小约为404GB,在模型启动运行时,需要将所有数据全部加载至内存中,且根据量化值的大小占用有所不同,如8bit量化则内存占用较4bit将近乎翻倍,所以本地PC部署此版本几乎不太可能。
本地体验建议使用蒸馏版本模型,相对较小,且不必依赖强大的数据中心级GPU,如不在乎生成速度,CPU也能跑,常见有以下几个版本:
| 模型名称 | 模型大小 | 备注 |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.1GB | 基于qwen蒸馏 |
| DeepSeek-R1-Distill-Qwen-7B | 4.7GB | 基于qwen蒸馏 |
| DeepSeek-R1-Distill-Llama-8B | 4.9GB | 基于llama蒸馏 |
| DeepSeek-R1-Distill-Qwen-14B | 9.0GB | 基于qwen蒸馏 |
| DeepSeek-R1-Distill-Qwen-32B | 20GB | 基于qwen蒸馏 |
| DeepSeek-R1-Distill-Llama-70B | 43GB | 基于llama蒸馏 |
| DeepSeek-R1 671B | 404GB | 未蒸馏 |
二、安装部署
1. 安装环境
云主机1台,3块英伟达T4显卡 (16GB VRAM)直通。
| 云主机 *1 | 系统 | Ubuntu22.04LTS |
| CPU | 32核 | |
| 内存 | 128 GB | |
| 硬盘 | 1TB SSD | |
| GPU | 3 * NVIDIA T4 (16GB) |
2. Ollama部署
Ollama官网:Ollama
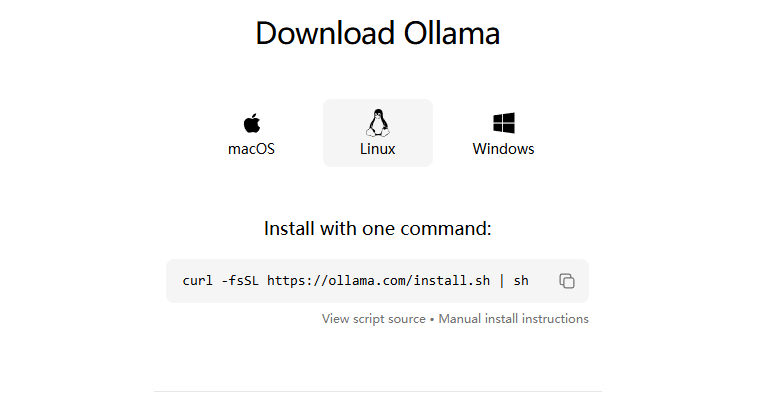
curl -fsSL https://ollama.com/install.sh | shLinux终端执行此脚本即可自动安装Ollama和对应显卡驱动(通过脚本查询GPU品牌自动下载安装驱动)
安装完成后测试安装是否正常:
ollama list 执行不报错,输出为空代表安装正常。
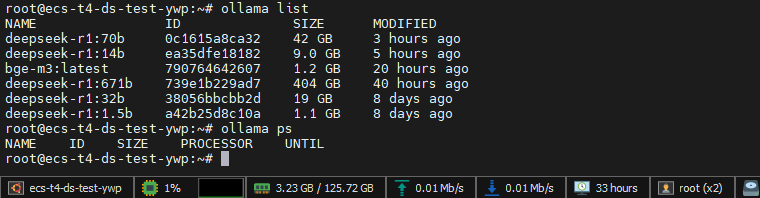
3. 模型拉取
执行以下命令拉取32b参数模型:
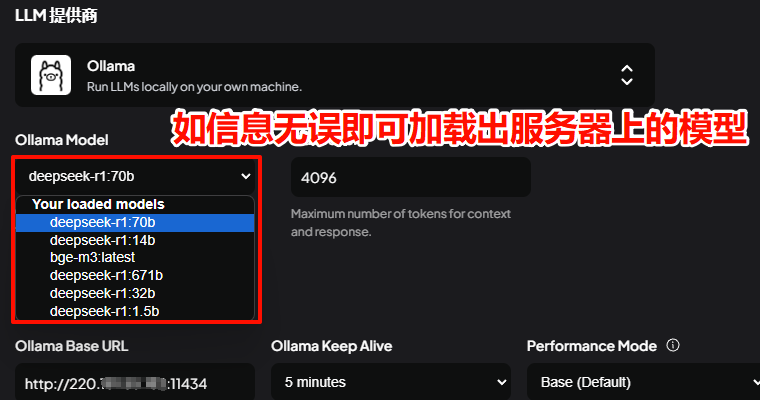
ollama run deepseek-r1:32b拉取完成后即可进入对话界面,至此已可以本机对接使用。
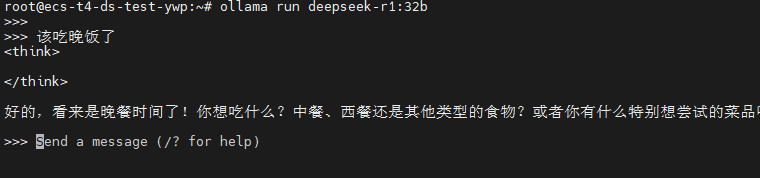
但!
我们都服务器部署了,是不是得映射到互联网或发布到局域网来团队使用呢?
现在的状态是不可以被互联网和局域网访问的,因为Ollama默认启动的监听是在本地环回地址的:

我们需要稍微修改一下配置。
4. 接口监听
我们要通过修改环境变量来修改监听接口信息,使用官方脚本进行拉取的Ollama是通过Systemd来管理的,所以修改环境变量要修改 /etc/systemd/system/ollama.service 增加如下配置:
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"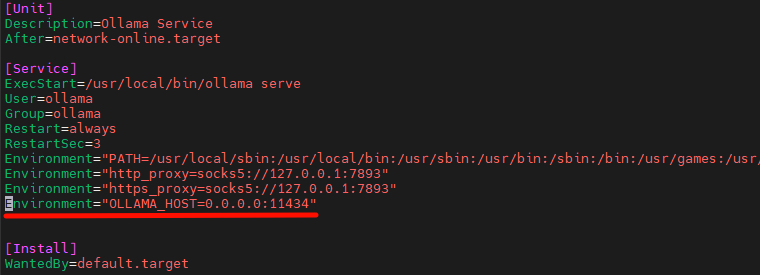
添加完成后保存退出:
systemctl daemon-reload
systemctl restart ollama.service
已经启用全部接口监听。现在可以通过局域网访问Ollama API接口,默认端口11434,可进行客户端的对接,如设备具有公网IP,则在无防火墙安全组等策略限制的情况下,已可以通过公网IP进行Ollama API调用。
三、客户端对接
客户端选择较为多样,Web客户端可选:WebUI、LobeChat,桌面客户端可选:WebUI、LobeChat等。
本次选用 AnythingLLM 作为演示,其他使用起来区别也不大,都是集成各模型服务厂商接口,如OpenAI、硅基流动、深度求索、月之暗面……. 到个平台申请API秘钥后即可直接调用。
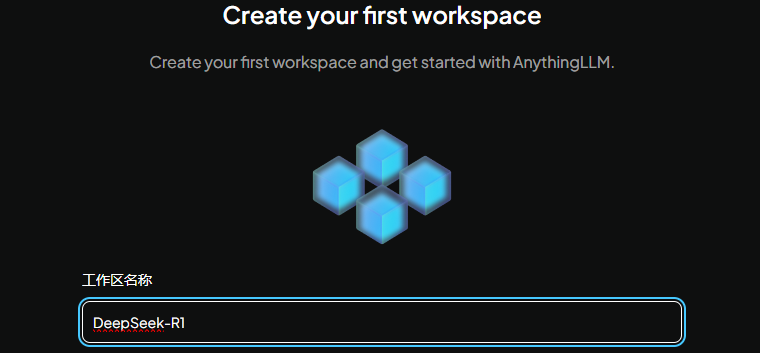
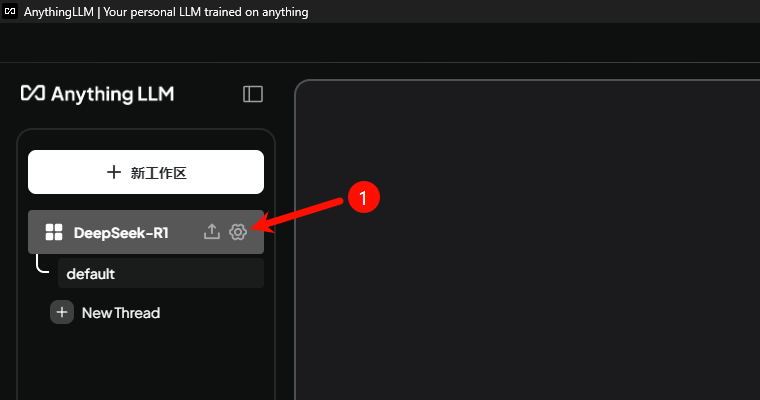
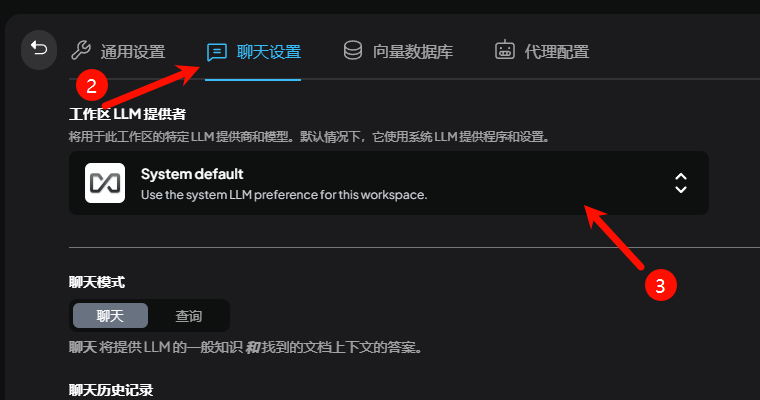

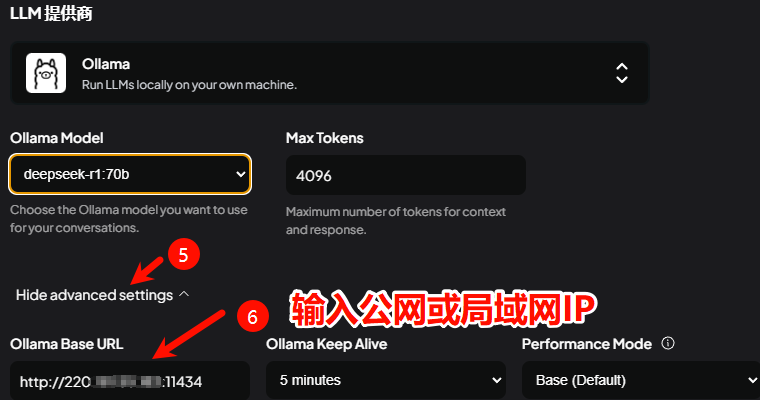

四、常见问题
1. 拉取模型太慢怎么办!?
代理!开代理,代理搭建方法就不分享了,得自己想办法哈~
如何配置代理?
还是修改systemd Ollama配置文件,替换为自己的代理地址,/etc/systemd/system/ollama.service
[Service]
Environment="http_proxy=socks5://127.0.0.1:7893"
Environment="https_proxy=socks5://127.0.0.1:7893"systemctl daemon-reload
systemctl restart ollama.service配置完成后重新拉取即可。
2. Error: llama runner process has terminated: cudaMalloc failed: out of memory
详细报错:
Error: llama runner process has terminated: cudaMalloc failed: out of memory
ggml_gallocr_reserve_n: failed to allocate CUDA0 buffer of size 8822759424
llama_new_context_with_model: failed to allocate compute buffersVRAM不足,如无法增加显卡或配置,可考虑启动统一内存,以允许 GPU 在内存不足时使用 CPU 内存 。
启动统一内存方法(systemd 管理):
[Service]
Environment=GGML_CUDA_ENABLE_UNIFIED_MEMORY=1 #启动统一内存systemctl daemon-reload
systemctl restart ollama.service可能会发现模型可以跑了,但性能极低。
五. 没有算力怎么办?
1.可以考虑上云
- 上云就上天翼云,天翼云息壤平台准备了大量的算力资源,提供开箱即用的算力,A10、910B等均可按小时付费,一站式智算服务平台新老用户均可免费体验两周 2500万Tokens免费使用。
- 阿里云:GPU算力1折起,1.9元每小时,适合低价体验AIGC之旅【链接直达】
- 腾讯云:Cloud Studio 10000分钟免费算力/月,无需部署、即开即用。【链接直达】
- 华为云:3步在线体验DeepSeek昇腾云适配版200万Tokens免费领。【链接直达】
2.模型整合服务商
- 硅基流动:注册即赠送 2000万 Tokens,可使用升腾算力,可直接调取API使用。【链接直达】
相关推荐:



![记录一次WordPress插件Redis Object Cache报错“Redis 无法访问: Connection refused [tcp://127.0.0.1:6379]”故障处理方法-万万没想到](https://oss.wanpeng.life/wp-content/uploads/2024/07/a0f1e0603bc52f8-220x150.png)


.png)



评论前必须登录!
立即登录 注册