 万万没想到
万万没想到一、前言
话不多说,先上一张图,我想大家已经懂了,谁现在工作中没经历过这样的痛苦呢?一个产品文档几百上千页,找些想要的信息可谓大海捞针,关键字匹配一下匹配到65535个结果……(wdnmd)
什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)
大模型的数据一般是静态的,无法覆盖最新或特定领域知识,RAG技术就允许动态引入外部知识库(如内部文档、新闻等),引用知识库中的内容来总结回答,减少幻觉,可大大提升LLM的时效性和专业性。
现在,利用RAG技术,我们每个人都可以拥有一个私人全能专家顾问,有什么问题,说人话就可以得到想要的答案!
二、专家哪里找
外面找
外面找家人力公司,让其提供人员
优点:省心、快速、立即上岗
缺点:可能 我说可能人品不行,偷东西,有跑路风险,干的越多要的越多,钱从你钱包一张张抽出,容易焦虑(tokens)
人力公司推荐:硅基流动【链接直达】
家里找
家里花钱培养一个,让其为我们服务
优点:诚实、可靠、听话、可调教
缺点:培养成本高、培养难度大
如何培养?看看我的经验:
【2025最新】Linux服务器部署DeepSeek-R1操作实践 | 企业级AI框架完整方案(Ollama)
【手把手教学】Windows系统部署DeepSeek-R1全攻略 | 本地部署实践指南(Ollama)
好,那现在我默认大家都已经找到自己的专家了。
三、如何对专家发号施令
首先要有一个工具来展示和记录我们提出的问题和专家给出的答案。
Cherry Studio(开源)【下载地址】下载并完成安装。
外面找的硅基流动
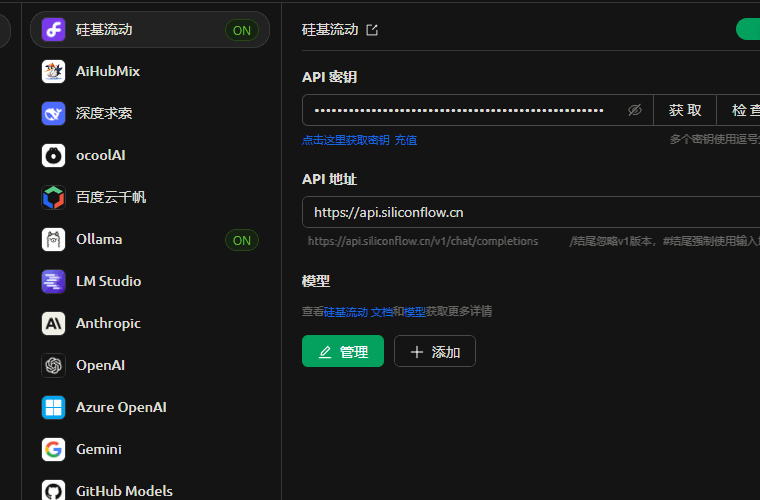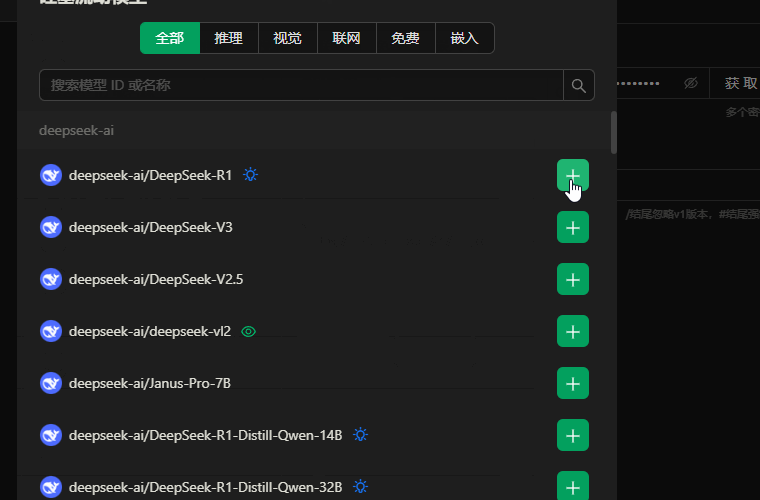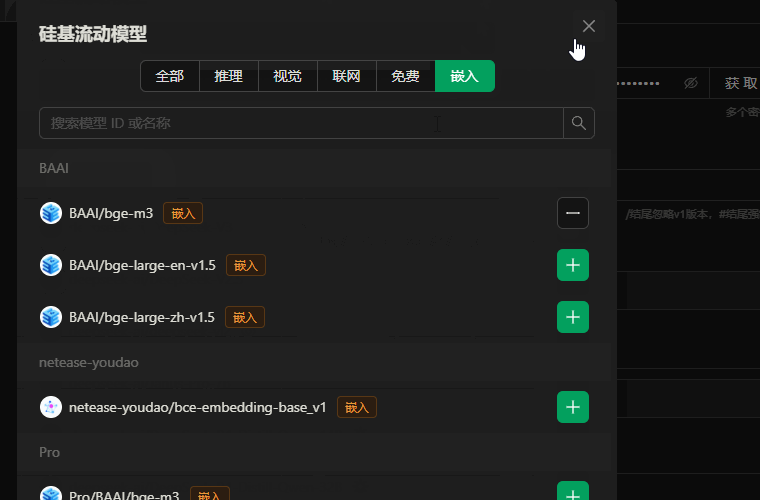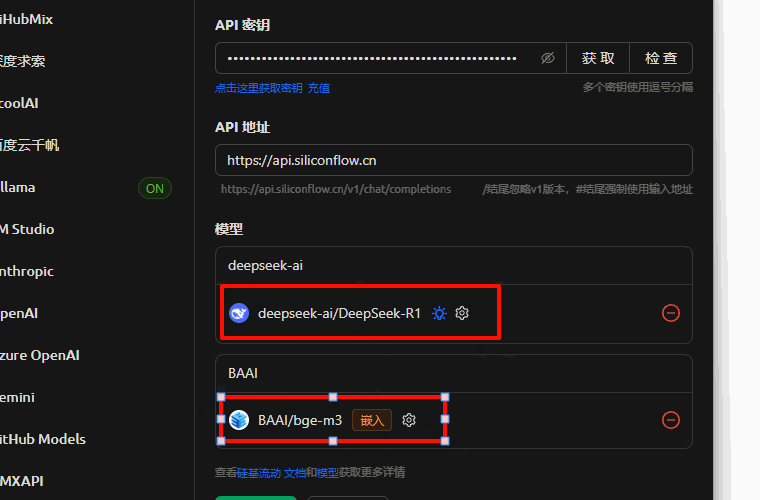
1. API秘钥生成
来到官网,如果没有账号先注册一个账号,通过我的邀请链接,我们各能获取到2000万Tokens。
[突然正经] 登录成功之后会跳转到模型广场,这里有各种各样我们可以调用的模型,我们来生成API秘钥来对接到刚才下载的Cherry Studio上。
左侧导航栏选择 “API 秘钥” ->”新建API密钥” -> 描述”Cherry Studio” -> “新建密钥” 单击进行复制

2. 模型添加
来到Cherry Studio,左侧导航栏最下方 “设置” 按钮 -> “模型服务” -> “硅基流动” -> “API秘钥” 处粘贴刚复制的秘钥 -> “管理” -> 添加 “deepseek-ai/DeepSeek-R1” -> “嵌入” 添加”BAAI/bge-m3″
主要添加两个模型:“deepseek-ai/DeepSeek-R1”,“BAAI/bge-m3”
BAAI/bge-m3模型:BGE-M3 是一个多功能、多语言、多粒度的文本嵌入模型。它支持三种常见的检索功能:密集检索、多向量检索和稀疏检索。该模型可以处理超过100种语言,并且能够处理从短句到长达8192个词元的长文档等不同粒度的输入。这里我们主要作为语义向量模型使用,用于解析我们上传的知识库,将文本转化为向量。
3. 连通性测试
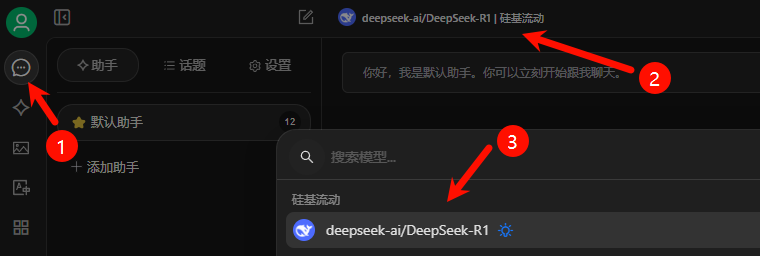
回到助手功能区,按下图顺序选择刚才添加的R1模型,随机发送内容测试是否可用。
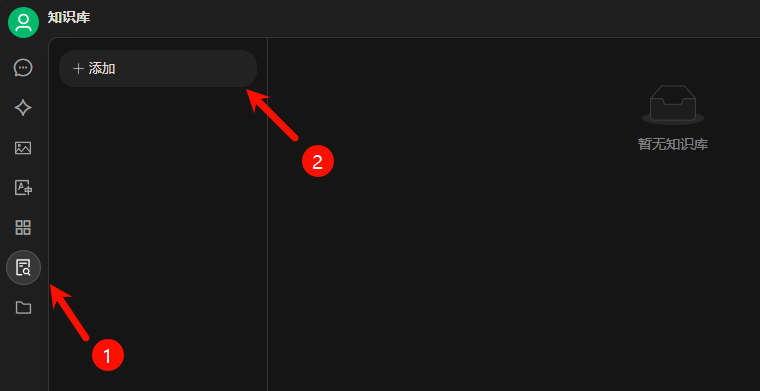
4. 知识库创建
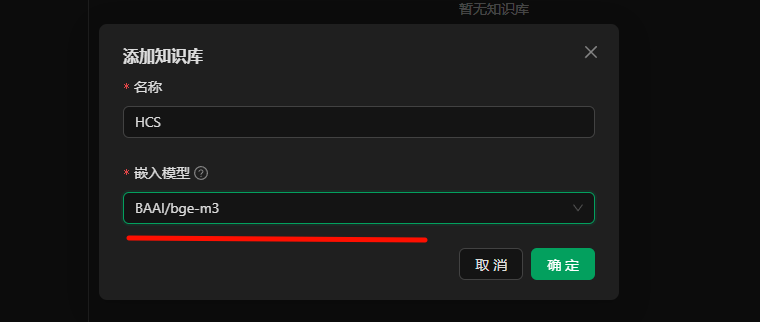
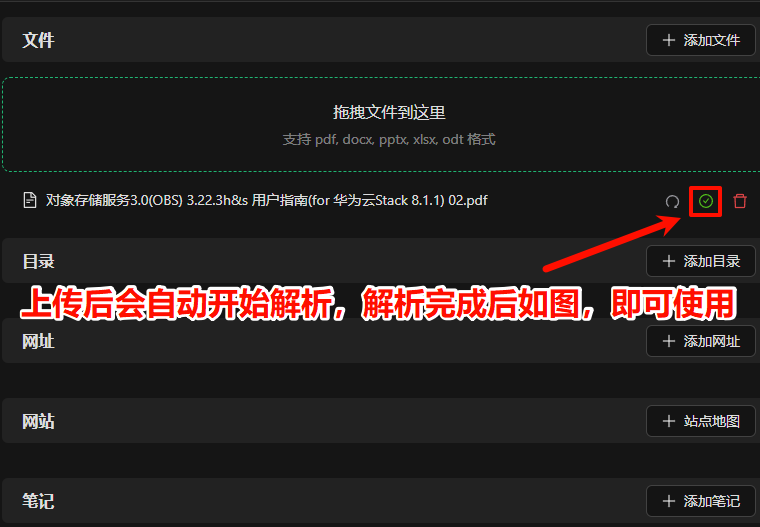
5. 知识库使用
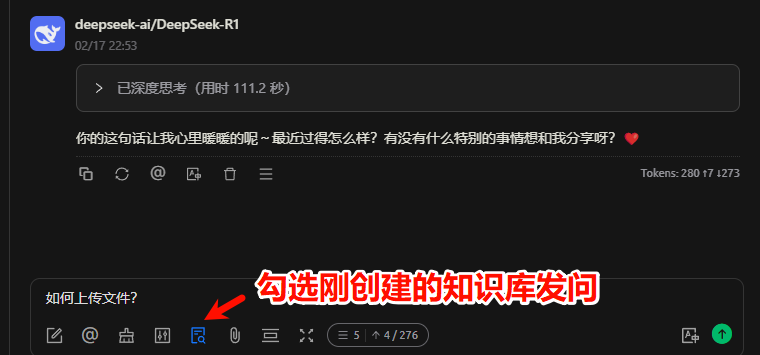
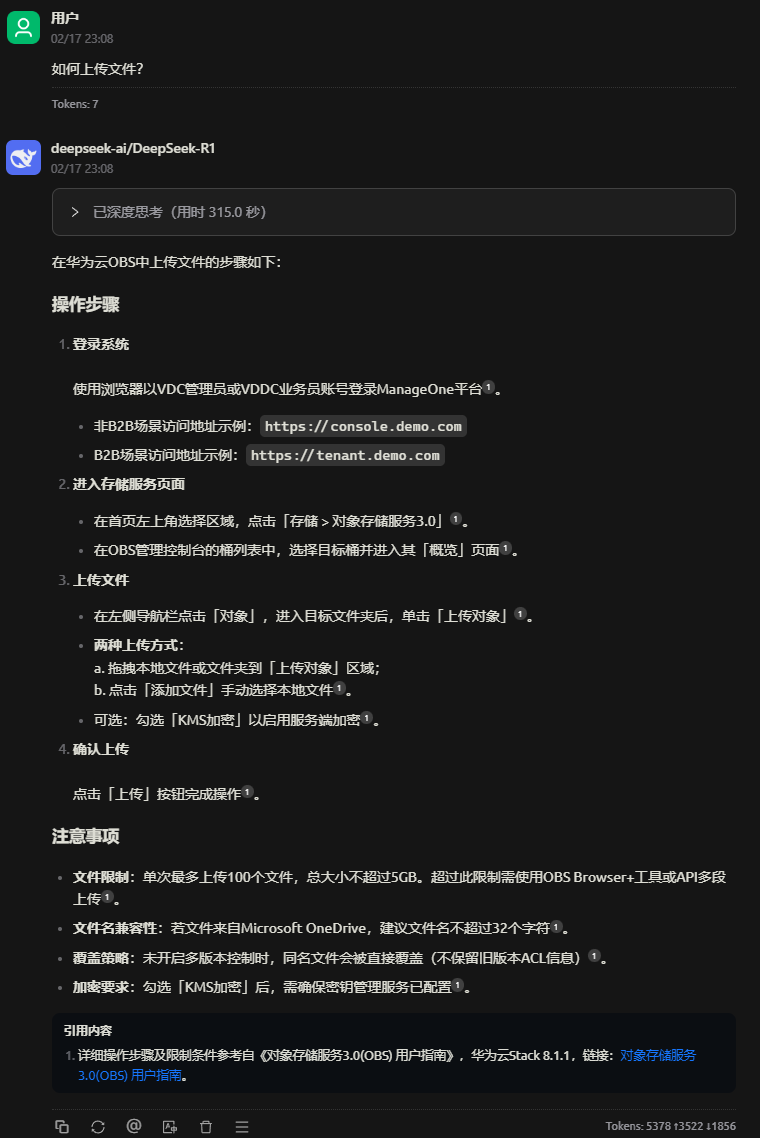
回复无误,可见引用的具体知识库中文档。
家里找的Ollama
1. bge-m3安装
Ollama部署主机上执行:
ollama pull bge-m3拉取成功即可,即可在后面步骤选中。
2. 模型添加
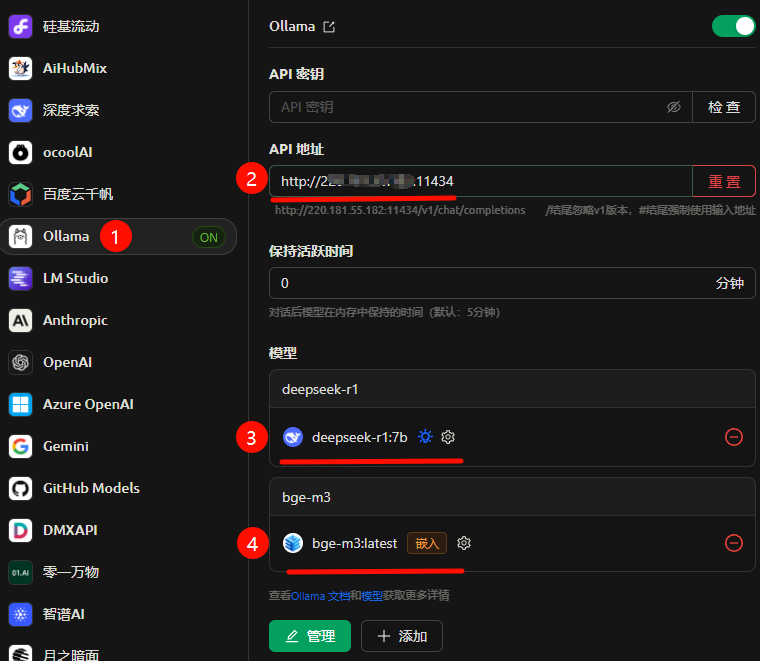
与上面对接硅基流动基本无差别,只需要修改API地址为我们部署的主机地址及端口即可。
3. 连通性测试
略
4. 知识库创建
略
5. 知识库使用
略
步骤 3 4 5 内容重复无区别,可参考“外面找的硅基流动”章节进行配置。
四、存在的问题
问题就是标题所说的只能个人使用,为什么?因为使用 Cherry Studio 创建的知识库和向量数据库都是存在本地电脑的,数据不能共享,所以无法团队使用。那么如何部署一个团队可用的知识库智能体呢?
且听下回分解(码字中)……



![记录一次WordPress插件Redis Object Cache报错“Redis 无法访问: Connection refused [tcp://127.0.0.1:6379]”故障处理方法-万万没想到](https://oss.wanpeng.life/wp-content/uploads/2024/07/a0f1e0603bc52f8-220x150.png)







评论前必须登录!
立即登录 注册